Musical DL
Unknown
For the capstone project of Machine Learning: Deep Learning (EN.601.682), we were tasked to form teams and apply deep learning to a topic of our choosing. My team of 3 attempted to create a deep learning based choral music synthesizer. Since singing voice synthesizers were (and still are) a relatively unexplored area of machine learning, we each decided to apply separate ML architectures to our problem—I chose to focus on the WaveNet architecture.
WaveNet
At the time, the state of the art in pure speech synthesis was Google's WaveNet architecture, used extensively by their Google Assistant. The DeepMind blog post about WaveNets does a really great job illustrating how they work, but at a high level, WaveNets are a type of convolutional network which seeks to directly model the distribution of real audio. WaveNets generate audio one sample at a time, and make use of a special type of so-called dilated convolution which allows the architecture to simultaneously handle both small scale and large scale details present in audio data.
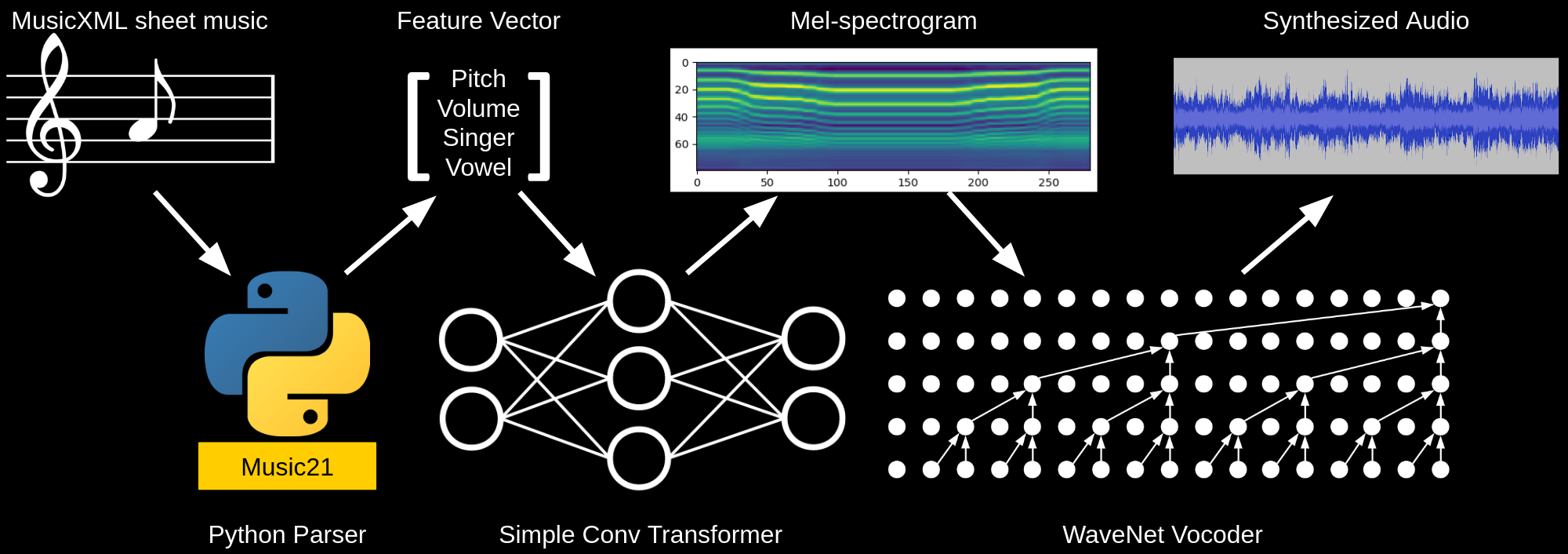
The specific implementation of WaveNet I used was the nv-wavenet by Nvidia, which included several optimizations allowing for much faster audio synthesis. The final speech synthesis architecture looked very similar to their Tacotron2 architecture, consisting of a WaveNet trained to generate audio from spectrograms, and a transformer trained to generate spectrograms given audio features—In their case the transformer converts text to spectrograms, while mine converts from features like pitch, volume, vowel, singer, etc.
For the application of choir synthesis, we found the VocalSet dataset which consists of 10 hours of monophonic singing by 20 singers. The data mostly consists of various scales and arpeggios sung on the vowels 'a', 'e', 'i', 'o', and 'u', along with several other vocal techniques. To train the WaveNet, I pulled out just the normal scales sung on each of the vowels, and had the WaveNet learn to reconstruct the raw audio given a spectrogram. I then built a simple transformer network which would generate spectrograms for the WaveNet. The features used by the transformer were either provided by the dataset itself (namely singer, and vowel), or were generated by analyzing the audio (pitch detection for pitch, and mean absolute value for volume).
For the last piece of my solution, I pulled in the work I had done during a recent hackathon, in which I had built a simple MusicXML parsing engine. With the parsing engine, I could read simple sheet music, and generate the features that the neural network understood, allowing me to have the network perform specific pieces.
Pipeline Diagram
Results
For a first attempt, I think it worked surprisingly well—the audio definitely sounded like a choir of singers, just all of them were tone deaf. As a last minute addition, I added an autotuner to correct the pitch deficiency, and actually got some surprisingly good results.
Danny Boy
Original (untuned)
Autotuned version
More Examples
'A' Arpeggio (untuned)
'E' Arpeggio (untuned)
Mary Had a Little Lamb (untuned)
Frère Jacques (autotuned)
The (Best) Worst Examples
Lessons & Future Work
From working on this project, and analyzing the results, I've learned two things: 1) audio is a very hard data domain to work with, 2) pitch detection is not a solved problem. The first one I mostly expected, but the second really surprised me—pitch detection is still an active area of research! Ultimately, a mostly vanilla WaveNet isn't suited for singing voice synthesis due to several assumptions made about spoken voice, namely that the dynamic range of pitches a spoken voice experiences is relatively small. The spectrograms used as feature input to the WaveNet do not possess a suitable range of frequencies for singing applications, and increasing the range runs into issues of not enough resolution, or too much memory used by the model.
Moving forward, I have continued to work on the problem of choral voice synthesis, and am starting to make good progress in my so voice! project. The experience I gained from this attempt has been invaluable in guiding my approach to building a more viable version.

